Why rare failures matter for the assurance of embodied AI
How smarter testing and statistical certification can strengthen safety evidence
Embodied AI systems – such as autonomous vessels, drones, and robots – do not live in datasets or benchmarks. They move through the world, interact with uncertain environments, and make decisions that affect people, assets, and operations in real time.
In safety-critical domains, the issue is rarely whether a system works in the average case. Failures tend to hide in the ‘tails’: unusual combinations of initial conditions, sensor noise, or environmental states that rarely arise under nominal operation, but carry severe consequences when they do.
When failures are rare, standard testing can easily spend most of its budget on uneventful scenarios and still say very little about how likely failure really is. What matters for assurance is not simply how many scenarios we test, but whether testing produces meaningful, defensible evidence about how likely failure is under realistic operating conditions.

From ‘safe by design’ to ‘safe in reality’
In control engineering and robotics, one common way of reasoning about safety is to define a candidate safe operating envelope: a set of conditions that prevents the system from evolving into an unsafe state.
A challenge is that these sets are often computed using simplified models. Real systems are messier. Sensors are imperfect, disturbances are uncertain, and the safe set may need to be checked against a higher-fidelity simulator or other evaluation model that is black-box, proprietary, or otherwise difficult to model exactly. As a result, a region that looks safe on paper may still contain hidden pockets of failure.
This creates an assurance gap. A candidate safe set is useful, but it is not the same as evidence that failures are sufficiently unlikely under realistic uncertainty. To close that gap, we need methods that do more than sample blindly: methods that actively search for rare failures while still allowing us to make statistically valid statements about the operating conditions that matter in practice.
A three-stage workflow: find, target, certify
To address this challenge, the approach in our recent paper, ‘Importance Sampling for Statistical Certification of Viable Initial Sets’ 1, is built around three core steps: find the likely failure region, target it efficiently during testing, and then statistically certify the resulting failure probability.
A simplified example to build intuition
The examples and interactive illustrations in this article are simplified, intuition-building examples. Their purpose is to show why rare failures are difficult to detect with ordinary sampling, and how surrogate-guided testing and importance sampling can improve the efficiency of failure-probability estimation and certification. The formal experiments in the paper go a step further: there, the objective is to certify candidate safe sets estimated using simplified models and then tested under more realistic dynamics and uncertainty.
Consider a simple driving example: a following vehicle is travelling behind a leader vehicle. Under most combinations of distance and speed, nothing dramatic happens. But near the edge of safe operation, an abrupt brake by the leader vehicle would lead to a collision.
If we want to make precise statements about how likely these accidents are, a challenge is that standard random testing based on data from nominal operations may spend almost all of its budget on uninformative safe cases and observe too few failures to estimate their probability with confidence. The key question is whether we can focus more of the testing budget on the rare cases that matter most, while still making precise statements about how likely those events are under nominal operation.
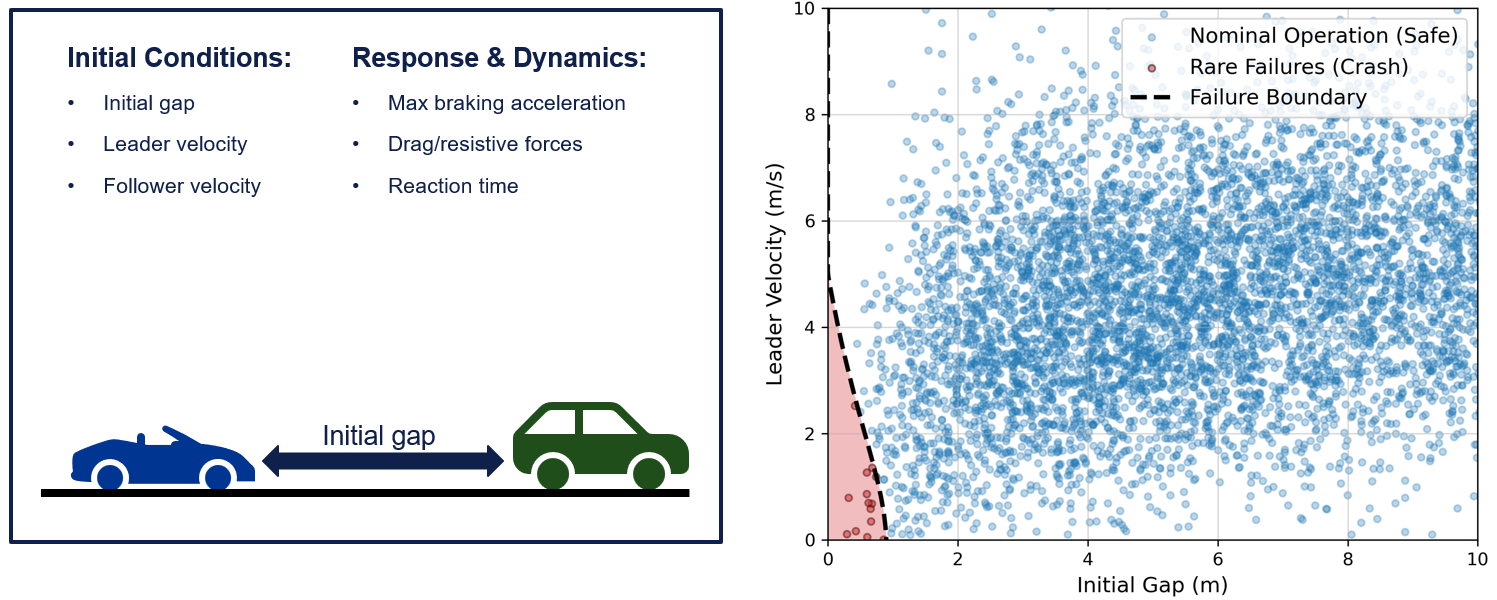 Figure 1: Nominal operation vs. rare failures. When the failure region lies in a small tail of the operating distribution, failures are rarely observed under ordinary sampling and can easily be missed.
Figure 1: Nominal operation vs. rare failures. When the failure region lies in a small tail of the operating distribution, failures are rarely observed under ordinary sampling and can easily be missed.
1. Find the failure-prone region
The first challenge is discovery. If failures are rare, waiting for them to appear by chance under nominal operating conditions is inefficient. Instead, we use a surrogate model – in our case a Gaussian Process (GP) – to learn where the boundary between safe and unsafe behaviour appears to lie. The model is updated as new test results come in, and it actively selects new evaluations in places that are likely to be informative.
This matters because the most useful test points are often not deep inside clearly safe or clearly unsafe areas. They are near the boundary, where a small change in conditions may separate a safe outcome from failure. By focusing attention there, the surrogate can identify the failure-prone region much more efficiently than ordinary random sampling.
Interactive chart 1: Surrogate-guided boundary discovery. Adjust the slider to see how the surrogate model guides testing towards informative points near the safe/unsafe boundary.
2. Target high-risk scenarios
Once we have identified a likely failure-prone region, the next step is to test it more aggressively. But a boundary alone is not enough. We need a full proposal distribution that places more probability mass in the regions where failures are likely, so that rare but important events appear more often during testing.
There are different ways to build such a proposal distribution. One option is to define a region that covers the likely failure area and sample from it. Another is to fit a lightweight probabilistic model that concentrates samples in the same area. The important point is not the exact construction, but that it makes rare failures easier to observe while still allowing the statistical correction in the final step to remain tractable. In the paper, this is paired with a tractable set-based characterization of the failure-prone region.
To keep the procedure statistically well behaved, we do not sample only from the high-risk region. Instead, we use a defensive mixture: part of the test budget is drawn from the targeted proposal distribution, and part remains drawn from the nominal operating distribution. A tuning parameter, alpha (α), controls that balance. Larger values place more emphasis on aggressive failure hunting, whereas smaller values preserve more of the nominal operating picture. This trade-off matters because it can improve efficiency when the surrogate is informative, while keeping the estimates robust to model error.
Interactive chart 2: Targeted sampling. Adjust the slider to see how tuning α shifts the testing focus from nominal driving operation to aggressive failure hunting identified by the surrogate model.
3. Certify failure probabilities
If we intentionally oversample risky scenarios, we cannot simply count the fraction of failures and call that the real-world failure rate. We have changed the sampling process, so we must mathematically correct for that change. This is where importance sampling comes in. Each test outcome is assigned a weight that accounts for how likely that scenario would have been under the true nominal operating conditions.
This correction gives us the best of both worlds: we see more informative failures during testing, but we still estimate the failure probability that matters under the original operating distribution. When failures are very rare, this can substantially improve sample efficiency compared with naive Monte Carlo testing, because the test campaign is no longer dominated by uneventful cases.
The final step is certification. In the paper, we derive a PAC-style upper bound on the failure probability, where PAC stands for ‘Probably Approximately Correct’. In plain language, this means that, with a chosen confidence level – for example 99.9% – we can state, based on the test results, that the true failure probability is no greater than the computed upper bound.
The interactive chart below illustrates how this plays out in practice. Compared with standard Monte Carlo methods, the importance-sampling-based approach converges more quickly, has lower estimator variance, and yields tighter bounds.
Interactive chart 3: Importance-weighted certification. Adjust the slider to see how the choice of proposal mixture, α, and number of testing samples affects the estimated failure probability and the resulting upper confidence bound.
What we saw in our case studies
The simplified example above illustrates the intuition behind the method. To evaluate the full framework, we then applied it to two different systems. Unlike the earlier intuition-building illustrations, these case studies correspond to the actual experimental setup in the paper, where the goal was to certify candidate safe sets under more realistic dynamics and uncertainty.
The first was an Adaptive Cruise Control (ACC) scenario, in which a following vehicle must brake safely behind a leader vehicle. In this case, the method starts from a candidate safe set computed using a simplified model and then evaluates it using a more realistic model with uncertainty. In this setting, failures were concentrated in a small region near the boundary of the candidate set. That makes the problem particularly difficult for standard Monte Carlo testing, because failures are both rare and easy to miss. In this setting, the importance-sampling-based estimator and statistical bound showed faster and more stable convergence than the standard approach.
The second case study considered a quadrotor flight scenario, where a drone must remain within a safe height envelope over time. This system is higher-dimensional, and the failure behaviour is sparse relative to the nominal distribution. That makes the testing problem somewhat different: the challenge is not only finding failures but doing so without overcommitting to an imperfect surrogate in a large state space. In this case too, the targeted approach produced lower variance and tighter bounds compared to the standard method.
These experiments suggest that when failures are rare and informative surrogate guidance is available, targeted sampling plus statistical correction can provide stronger assurance evidence than naive sampling alone. For the full technical details, including the formal guarantees and empirical results, we refer readers to the paper: ‘Importance Sampling for Statistical Certification of Viable Initial Sets’ 1
Why this matters for assurance
A useful assurance argument needs more precise statements than ‘we tested a lot’ or ‘we did not observe failures in this sample’. In rare-event settings, those statements can be misleading, because ordinary testing may simply miss the low-probability regions where the most consequential failures occur. The value of the workflow above is that it turns testing into a more targeted search for evidence while still preserving a statistically valid link back to real operating conditions. This matters because, in realistic settings, any testing budget comes with constraints in time, cost, and potentially also risk – especially when physical experiments are involved.
That does not make the resulting guarantee unconditional. Any such claim still depends on assumptions: that the simulator or physical test setup reflects the real system well enough; that the nominal operating distribution is appropriate; and that the statistical conditions behind the certification are satisfied. But conditional evidence is still valuable evidence, especially when those assumptions are explicit and can be examined, challenged, and updated within a broader assurance case.
What this changes is the kind of claim we are able to make. Instead of saying ‘we found no failures in this sample’, we can make a justified, conditional, and quantified statement such as: ‘Under these assumptions, we can place an upper bound on how likely failure is.’ That shifts the conversation from ‘we did not observe any problems’ to a much stronger foundation for assurance, and a more meaningful way to reason about risk in real-world embodied AI systems.