Safe, responsible and effective use of LLMs
This article elaborates on the strengths and limitations of large language models (LLMs) based on publicly available research and our experiences working with language models in an industrial context. We consider diverse concerns, including unreliable and untrustworthy output, harmful content, cyber security vulnerabilities, intellectual property challenges, environmental and social impacts, and business implications of rapid technology advancements. We discuss how, and to what extent, these risks may be avoided, reduced or controlled, and how to harness language models effectively and responsibly in light of the risks.

1 Introduction
NOTE: Readers familiar with LLMs may want to skip to section 2.
A language model is a probabilistic model for predicting the next word (or token, an even smaller language unit than a word) to appear in a sentence, given a particular context. Such models are trained on a set of example sentences known as a corpus and are iteratively refined to improve prediction capabilities over time.
Following the success of the transformer architecture 1 proposed by Google in 2017 for machine translation, two kinds of transformer sub-architectures were adopted by Google and OpenAI respectively in 2018 to build their language models. These two language model types are now known as BERT 2 (bidirectional encoder representations from transformers) and GPT 3 (generative pre-trained transformer) (see Figure 1).

Figure 1: BERT versus GPT models.
BERT is trained to fill in randomly masked parts of a sentence. Contexts before and after the masked parts are used to recover the missing information. This mimics humans doing cloze tests 4. On the other hand, GPT is trained to autoregressively predict the next word/token (see Figure 2). Only the preceding context, called the “prompt”, is used to generate the word/token right after, and the generated word/token is then appended to the context for further generation until an end token is received or the maximal generation length is reached. The maximum amount of text the model can handle in a prompt is called the “context window”.

Figure 2: Illustration of how an autoregressive model, such as a GPT, generates the next word/token.
Initially, BERT outperformed GPT in various downstream language tasks. However, as models and training data scaled up, GPT’s capabilities excelled while BERT’s performance plateaued. Consequently, today’s dominant language models are based on the GPT architecture, characterized by their unprecedented size. This trend has led to the widespread use of the term “large language model” (LLM). While the initial LLM could only handle text, we now see more multimodal models that can handle images, text and speech as input and/or output.
Custom training of LLMs is impractical for most companies due to resource costs, expertise demands, and data privacy issues. Instead, leveraging existing models or APIs is a more pragmatic choice. Even companies with the resources to train LLMs will typically use pre-trained commercial or open-source models as a basis for their LLMs. LLMs are usually accessed via (public or private) APIs, but smaller models can be run locally on laptop computers or even on mobile devices.
There are two main types of models or APIs:
- Base model/API: This is used to complete text based on a single prompt.
- Chat model/API: Essentially, it performs dialogue completion and creates the illusion of interacting with a human through a chat. The chat model is fine-tuned from the base model using human-verified high-quality dialogues. This fine-tuning process aligns the model with common human values and preferences. In most cases, the name of the chat model includes terms like “instruct” or “chat” appended to the base model’s name.
While LLMs inherently only generate text, they can be set up to interact with, or make use of, other technologies and tools. For example, a language model may be given permissions to trigger certain actions, such as executing web searches, querying databases, calling APIs or running code. The output of such actions can then be fed back into the prompt so that the language model can process it before providing its final response. The workflow may be predefined and fixed, or the language model may act as an “agent” that decides itself how and when to use tools. One can even have systems of interacting agents that collaborate or compete to achieve some goal. With multimodal models, different capabilities are more directly integrated through common embeddings for different modalities, and such models can make use of different modes of information as needed (e.g., text, images, sound).
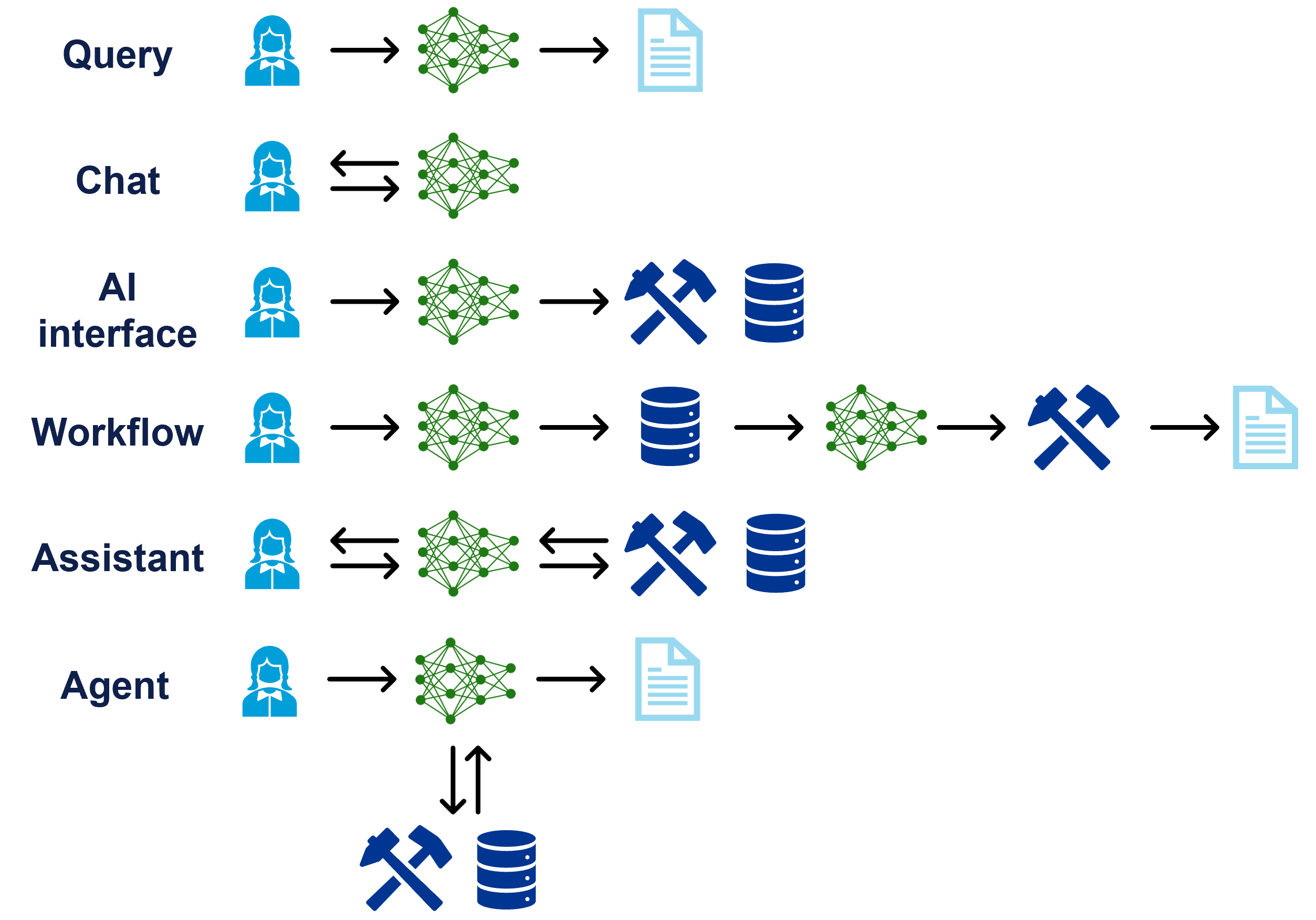
Figure 3: Different ways to use LLMs.
Typical uses of LLMs
Only creativity limits how LLMs may be used, but here are some typical use cases (note that all of these have limitations and associated risks, as discussed further below):
-
Content generation: LLMs can be used to generate any kind of text, for example stories, poetry, articles and social media content. They may also generate other types of content, like synthetic datasets or code. Multimodal models (or models connected to other tools) may even generate images, speech or video.
-
Coding and debugging: LLMs can help with code suggestions, error detection, generating boilerplate code, as well as automatic generation of documentation and comments for codebases.
-
Content summarization and analysis: LLMs can quickly process large amounts of text and provide summaries. This can for example be used to extract relevant information from reports, interview or meeting transcripts, medical records or legal documents. LLMs can also be used to detect the sentiments and opinions from texts such as user reviews and social media posts.
-
Translation and adaptation: LLMs can be used to translate content between languages and styles, and for adapting content to particular settings or contexts. This includes translation of code between programming languages.
-
Information retrieval: LLMs can respond to specific queries by leveraging the knowledge contained in their training data and processing information provided in the prompt. Specifically, an LLM may be used to process results obtained from search engines, databases or API calls to enhance information retrieval from external sources.
-
Content checking, moderation and filtering: LLMs can be used for correcting spelling and grammar, detecting and flagging inappropriate, offensive, or harmful content, identifying and filtering out spam messages, detecting fraud attempts, and so on. They can also be used to check that documents adhere to a set of standards or requirements or fit a prescribed format.
-
Chatbots: Chatbots are basic conversational interfaces to LLMs that can understand and respond to user inputs in natural language. This is common in customer support to answer common queries about products, services and procedures. Chatbots may also be used to provide counselling or act as tutors on various subjects, offering explanations, giving hints, pointing out mistakes and making corrections.
-
Copilots: Copilots are assistants that provide suggestions, complete tasks, or aid users in real-time within a specific application or context. Examples include writing or coding assistants. The LLM used in a copilot may be fine-tuned and prompted to act in a certain way in a desired role. Copilots often have access to (with certain risks) users’ documents and files in order to provide assistance beyond the LLM’s own ‘knowledge’.
-
Agents: LLM agents are (more or less) autonomous systems that can perform complex (scheduled) tasks, involving multiple systems and/or datasets. Example use cases can be virtual customer service agents that can (with access to command or APIs) handle complex multi-step transactions, such as booking travel arrangements. Agents go beyond chatbots and copilots in the sense that they also can execute actions based on their own generated content. Agent LLMs are empowered with given access or management privileges to certain system features/functions, such that they can perform automated operations within the system. Depending on the context, the latter introduces risk of harm from the actions the LLM executes.
-
Collaborative AI agents: Multiple LLM-powered agents can work together to achieve a common goal. An example is a pipelined workflow automation in business environments where different agents perform specific tasks in the process/chain. Different LLM instances may also be used to act in particular roles, similar to a team of humans. The strength of collaborative LLMs comes from the possibility of specifically training (more often fine-tuning) or prompting each LLM to be very good at one task.
-
Semantic user interfaces: LLMs can serve as natural language user interfaces to control any kind of software (which in turn may control any kind of hardware). For example, a virtual assistant based on an LLM may be used to perform tasks like setting reminders, providing weather updates, managing schedules or controlling the lights and other appliances in a home. In industrial settings, LLMs could provide interfaces to databases, control systems, simulators or other software. LLMs can also be used as interfaces to other generative AI systems, such as image or video generators. Multimodal models may serve as combined voice, text and image user interfaces, enabling humans to interact with systems in the same way they interact with other humans.
2 What are the strengths and limitations of LLMs?
Already in 2016, the first report came of a machine passing the Turing test, which tests whether a human can tell apart a machine from a human when interacting with both via a text-based interface 5. When ChatGPT was released in 2022 6, it astonished the world with its remarkably human-like interactions. Since then, AI-generated content has become increasingly hard to recognize. LLMs are performing tasks today that would have been hard to believe for most people only a few years ago. However, amidst the enthusiasm about LLMs and generative AI in the media and marketing, it is crucial to be critical about the AI capabilities and limitations. The promoted examples are often cherry-picked; in reality, the LLMs can be inconsistent and unpredictable. This poses challenges for applications in real-world business- and production settings.
This section attempts to explain the inherent limitations and capabilities of current LLMs. Section 3 discusses the risks that emerge from both the strengths and weaknesses.
2.1 Fluency, grammar and style
LLMs are good at writing fluent and grammatically correct text. They also have a remarkable ability to produce content according to the different styles that we ask for. This can be both useful and amusing, but it should not come as a surprise if we consider how language models are trained on large corpora of data to predict the next token: It is likely that most of the sentences in the training data are grammatically correct, and that most of the words in the training data are spelt correctly. Thus, grammar and spelling are attributes of text that manifest as strong correlations in the training data. Similarly, style is about the patterns of expression used in different contexts (for example the style is different in complaint letters, birthday speeches, news reports or Shakespeare plays). Programming languages, even more than natural human languages, conform to syntax rules and style conventions, which also manifest as correlations in the training data. LLMs are good at learning such patterns and can therefore be good at suggesting “boilerplate code” for common applications.
The flip side of being good at learning style is that LLMs may acquire an innate tendency towards styles that are dominant in the training corpus and perpetuate biases present in the data it has seen. For example, an LLM trained on a mainly English corpus may tend to anglicise text in other languages, and will not work well for contexts or languages poorly represented in the training data 7. LLMs may also reinforce gender stereotypes by the examples and words they choose 8. In other words, not all “style” patterns learnt from the training data are desirable.
2.2 Knowledge and understanding
LLMs are good at answering questions about “common” factual knowledge. Again, this may not be surprising, considering that claims repeated many times in different sources would be picked up as strong correlations by an LLM. LLMs have the advantage of being trained on “the entire internet”, where even topics that are obscure to most humans may be common to humanity.
To the extent that LLMs can “know” anything, the knowledge originates from, or reside in, one of two places:
-
Parametric memory: When an LLM is trained, its parameters are tuned to take specific values. During training, the LLM essentially compresses the training data (including any human feedback). Conversely, the generation of responses from prompts is a form of decompression.
-
Context memory: Prompts provide contextual information that guides the response of the LLM. In addition to queries from humans, prompts can include information received or requested by the LLM from other sources or tools. The input prompt is translated into an embedding vector space and propagated through the layers of the language model in a way that is determined by the model parameters. This is how the LLM fuses the context memory and parametric memory to produce and output. An LLM is capable of "in-context-learning", where a set of examples are given in the prompt, and the model is able to generalize to new examples.
While LLMs' ability to compress knowledge and learn in context is impressive, there are several issues with both the parametric and context memory (and these can only partially be mitigated by coupling to other tools):
-
“Garbage in, garbage out” (GIGO): Information in the training data or provided in prompts is not necessarily correct, which can cause the LLM to reproduce errors.
-
Hallucination. Hallucinations happen when LLMs "make stuff up". This is in part because the compression of the training data by the model is not perfect, but could also be a sign of overfitting to the training data and poor generalization and extrapolation. In addition, ambiguity and lack of context in the prompt may cause the LLM to “misunderstand” or make wrong associations. On top of this, since the LLM generates output token-by-token probabilistically, there is some randomness in the responses, and the model may tend to “prioritize” style and fluency over factual correctness. The effect of hallucinations is made worse by the LLMs’ tendency to write convincingly, their limited “awareness” of what they don’t “know”, and their limited ability to be self-critical and express uncertainties. It is common for LLMs to be “confidently wrong”. Ways of combating hallucinations are discussed further below.
-
Distractions. LLMs can be distracted by irrelevant information provided in a prompt. This is because LLMs use an attention mechanism to weigh the importance of different parts of the input text and take context into account when generating responses, which can sometimes lead to suboptimal handling of irrelevant details. Distractions in prompts can lead LLMs to generate responses that are inaccurate or irrelevant.
-
Limited context memory. As one exceeds the context window, for example during a sequence of interactions with an LLM, it will eventually drop and “forget” the earlier parts of the exchange. LLMs typically struggle to effectively account for text located in the middle of the context as opposed to the beginning or the end 9. This limitation can severely influence the model's "comprehension" and the coherence of the generated content.
-
Lack of domain and cultural knowledge: LLMs often struggle with domain-specific knowledge deficits, particularly in emerging fields, due to limited training data coverage and insufficiently diverse pre-training datasets. Similarly, they also lack knowledge of languages and cultures that are poorly represented in the training data.
-
Outdated knowledge: An LLM only knows what was in the training data at the time it was trained, and any more recent information needs to be provided through the prompt (for example by calling APIs or querying updated databases).
-
Unstructured knowledge: It is a topic of debate whether LLMs effectively learn a “world model”. What is clear is that their knowledge is implicitly encoded in the neural net weights, as opposed to being deliberately structured in the form of a relational database, ontology or knowledge graph. In some sense, the knowledge of an LLM is tacit rather than explicit, and therefore not transparent. (On the other hand, LLMs can interface with structured knowledge representations to help retrieval of information, as discussed below.)
-
Lack of quality data: Today’s leading LLMs are trained on “the entire internet” and other large corpora of data. They rely on the data containing meaningful correlations. However, given that LLMs have accelerated the speed of content production, there is a fear that the internet will eventually be swamped with AI-generated data, which may contain errors and biases. New models may then be trained on such “polluted data. There is evidence that this can lead to “model collapse”, where the performance of a model declines as it is trained on its own output 10.
-
Tokenization: The way text is divided into tokens influences the internal representation of knowledge in the LLM. This can influence performance on downstream tasks, and the tokenization optimal for one language may not work well for another 11.
2.3 Guessing versus reasoning
Many benchmarks are measuring the performance of LLMs on standardised test or puzzles and reporting human-like performance (e.g., 12). The OpenAi CTO, Mira Murati, even stated in June 2024 that “GPT-3 was toddler-level, GPT-4 was a smart high schooler and the next gen, to be released in a year and a half, will be PhD-level” 13. However, such benchmarks and claims are questionable. One reason for the apparent high achievement of some LLMs on problem-solving benchmarks is that they are actually just retrieving information. There is a lot of information on the internet, including pages containing answers or solution templates for standardised tests and puzzles. Moreover, because they have seen many examples and patterns of reasoning, LLMs are good at “guessing” the answer. The challenge is that an LLM may confuse patterns in style with patterns in meaning. For example, when presenting an LLM with a common puzzle with a slight twist, the LLM may answer based on the pattern of answers it has seen rather than picking up the crucial detail that changes the solution 14. (We experienced this when asking GPT-4 about variations of the Monty Hall problem.)
The psychology professor Daniel Kahneman introduced the concept that human brains have a “System 1” and a “System 2” mode 15. System 1 is fast, automatic and unconscious, but also emotional and stereotypical. On the contrary, system 2 is slow and requires conscious effort and logical reasoning. Professor Subbarao Kambhampati advocates that LLMs are akin to an external System 1, and that we should be content with that and not expect them to have System 2 capabilities 14. In another paper, Kambhampati and coauthors conclude that the claimed improvement in reasoning achieved by LLMs with Chain of Thoughts (CoT) prompting “…do not stem from the model learning general algorithmic procedures via demonstrations, but rather depends on carefully engineering highly problem specific prompts” 16. In other words, the improvements come at the cost of human labour. They have also devised a benchmark where leading LLMs still perform very low (0-36%) on planning tasks even when using CoT. Similar conclusions were reached in a study that included over 1,000 experiments, which according to the authors provided compelling evidence that emergent abilities of LLMs can primarily be ascribed to in-context learning (i.e. it is related to clever prompting) 17.
Symbolic reasoning and computations are areas where computers outperformed humans decades ago, yet today’s state-of-the-art LLMs struggle with simple problems. This is not strange, given that today’s LLMs are feed-forward neural nets without the ability of recursion or adaptation, and they use the same computational resources for problems irrespective of their computational complexity. Hybrid systems that exploit capabilities of symbolic manipulation and computation may be able to bridge the step to “system 2” level intelligence. For example, DeepMind announced in January 2024 that Alpha Geometry achieved mathematics Olympiad performance on geometry problems 18, but in reality it is only using a language model to interface with a symbolic engine and not doing the heavy symbolic reasoning itself (as pointed out by Hector Zenil 19).
It has been found that when LLMs are asked to be critical to themselves, they may actually perform worse 20. A possible explanation for this is that LLMs tend to wrongly identify correct claims as errors while overlooking real errors, and therefore errors accumulate with iterations of criticism rather than being removed.
In the end, does it matter whether LLMs are really reasoning, or simply very good at retrieving information, guessing, and in-context learning? That depends on the use case, and on how easy it is to check the LLM's answers and detect errors. In many cases "guess and check" (trial and error) is an efficient strategy to search for solutions, but it seems that LLMs should only be relied on for the guessing part. Adding humans in the loop or coupling LLMs to external tools such as reasoning engines can help with the checking part.
3 What are the risks associated with language models?
Like any technology, LLMs can have both wanted and unwanted consequences. Some consequences are predictable and well understood, while others are unpredictable and poorly understood. This space of consequences and associated uncertainty constitute the risks related to the technology (including opportunities, i.e. "positive risk"). Risk management is the effort to reduce uncertainty and control consequences to maximise benefits and minimise harms.
To be able to manage LLM risks, we need to understand the LLMs’ capabilities and limitations. However, we also need to examine how they are developed, used and managed. We must be able to trust that the interests of various stakeholders are safeguarded by the LLMs and those who develop, manage and provide services based on them.
The consequences of an LLM’s capabilities and limitations depend on how it is used. The range of concerns and possible impacts are very different if, for example, journalists use the LLM to suggest news headlines, if a company employs an LLM chatbot to talk to their customers, if an employer uses LLMs to screen job applications, if a doctor uses an LLMs to summarize health records, or if the police use an LLM to summarize interrogation and match information to other sources. For some applications, the main concern may be to avoid misinformation, while other applications bring concerns about privacy, concerns about harmful content, reliability, and so on. Therefore, the risk related to LLMs must always be evaluated in context.
Beyond the possible failures and unanticipated side effects of using LLMs for benign and legitimate purposes, there are also the possibilities of misuse, for example to cheat on school work, commit fraud, produce fake news, and so on. These risks of adversarial uses grow as the capabilities of the models improve.
The subsections below discuss some selected risk categories relevant to language model use and development, specifically in the context of industry and business.
3.1 Unreliable, untrustworthy or harmful output
Maybe the most obvious risk related to language models relate to their output. The consequences depend on what the output is used for, including an LLM agent’s level of autonomy, system privileges and access to tools.
The risks from use of language model output stem from their strengths as much as their weaknesses and may from both good and bad intentions.
- Hallucinations: A well-articulated but hallucinating LLM may lead us to make suboptimal or bad choices based on wrong or inaccurate information.
- Adversararial use: Adversaries may use LLMs to intentionally fool and manipulate us. In such cases, it is not hallucinations that are the problem, but rather the LLM's ability to be convincing.
- Harmful content: Even if the content generated by an LLM is correct, it may be harmful. For example, an LLM may provide information about making bombs, performing crimes, committing suicide and so on.
- Biases: Biases that are perpetuated and reinforced by the LLM could also lead to societal or individual harm, for example by contributing to discrimination and unfair treatment.
Hallucinations in LLMs occur because these models are trained on vast amounts of data from the internet, books, and other sources, encompassing both factual and non-factual information. They generate responses based on patterns and probabilities rather than understanding or verifying the truth. As a result, LLMs can confidently produce information that appears credible but is inaccurate or false. For instance, an LLM might:
- Fabricate statistics or data points.
- Claim wrong answers to calculations because they are not actually computed.
- Misrepresent facts, events, or figures.
- Generate plausible-sounding but entirely made-up information. When LLMs are used in workflows that rely on their outputs for decision-making, planning, or execution, hallucinations can have a cascading effect, leading to errors in downstream processes. For example, if an LLM is used to generate a report that feeds into an automated decision-making system, an error in the report could lead to incorrect decisions being made without human oversight. Overreliance on LLMs without adequate oversight can lead to misinformation and misjudgments based on incorrect outputs. Detecting hallucinations can be particularly challenging because LLMs can generate responses that are highly plausible. Users may not have the expertise or resources to verify every piece of information provided by the model, especially in real-time applications. This increases the risk that hallucinated content will go unnoticed until it has already influenced critical processes.
Methods exist to control the behaviour of LLMs to improve the trustworthiness of responses and reduce harm, as discussed in section 4. However, even using these approaches to control LLM output, the probabilistic nature of LLMs can make them behave in unpredictable ways. In an industrial setting, it may not be tolerable if a task is performed correctly/adequately only 80% of the time, and LLM based applications may be too unreliable for production settings.
3.2 Cyber security risks
As the adoption of Large Language Models (LLMs) continues to rise in various applications, the spectrum of associated cybersecurity risks is also expanding. LLMs can be targets of cyber attacks, but also provide a powerful tool attackers. Luckily, they can also be useful for defenders. This has implications for how we think about cybersecurity in the age of LLMs.
LLMs as targets
The following list outlines some potential vulnerabilities associated with LLMs, but it is not exhaustive 21:
-
Prompt Injection: Malicious inputs can manipulate LLMs to perform unintended actions or expose sensitive information, including jailbreaking prompts to circumvent moderation and alignment of LLMs. The issue is essentially that LLMs do not separate the code (i.e., the system prompts) from the data (i.e., user prompts), which means that any instructions can in principle be overridden. There exist both white-box and black-box methods that can be used to automatically find prompts that can jailbreak an LLM and make it do essentially anything you want 22,23,24. This includes making it always respond with the termination token (i.e. block any response) or generate very long/infinite responses (i.e., potentially spending excessive computational resources).
-
Insecure Output Handling: Inadequate validation and sanitization of LLM outputs can lead to security vulnerabilities like remote code execution.
-
Training Data Poisoning: Malicious alteration of training data can introduce biases, backdoors, or compromise the integrity and functionality of LLMs.
-
Model Denial of Service: Exploiting the resource-intensive nature of LLMs by overwhelming the system with resource-heavy tasks can cause service degradation.
-
Supply Chain Vulnerabilities: Dependencies on third-party data, models, and infrastructure can introduce vulnerabilities if these components are compromised.
-
Sensitive Information Disclosure: LLMs may inadvertently leak confidential information embedded in their training data or through their interactions. It is also possible to tease out information from system prompts that the model provider did not intend the user to see, which in turn may be used to design new attack strategies. In some cases only an embedding vector is exchanged with the model, but this does not ensure privacy, as there exists methods for reproducing prompts by embedding inversion 25.
-
Insecure Plugin Design: Security flaws in plugin designs can lead to unauthorized actions or data exposure.
-
Excessive Agency: Granting excessive permissions or functionality to LLMs can result in unintended or unauthorized actions.
-
Model Theft: Unauthorized access and theft of proprietary LLM models can result in economic losses and competitive disadvantages.
To address these risks effectively, organizations must implement robust security measures, including secure development practices, access controls, input validation, output sanitization, and continuous monitoring and auditing of LLM systems. A systematic approach for identifying and addressing potential vulnerabilities is crucial. Each vulnerability presents unique challenges that require targeted mitigation strategies to ensure the secure deployment and operation of LLMs across different applications.
LLMs as attackers LLMs possess the capability to automate sophisticated "hands-on-keyboard" cyber-attacks, transforming the dynamics of cyber warfare 26. By leveraging the high-level natural language understanding and processing abilities of models like GPT-4, attackers can automate the complete cycle of a cyber attack, including post-breach activities traditionally requiring human intervention. This includes running shell commands, controlling network operations, or manipulating system processes across diverse operating systems like Windows and Linux. LLM-based systems can utilize a modular agent architecture that integrates summarizing, planning, navigating, and retrieving past attack experiences to optimize attack strategies. This not only increases the speed and scale of attacks but also allows attackers to execute complex, contingent attack sequences with minimal human input. The automation of such tasks can significantly reduce the cost and increase the frequency of cyber-attacks, posing serious challenges to current cybersecurity defenses which are mostly designed to counter human-led operations. This evolution marks a pivotal shift in security dynamics, emphasizing an urgent need for developing more advanced, AI-integrated defense mechanisms that can anticipate and counteract these automated threats.
LLMs as defenders While LLMs introduce new vulnerabilities and can be used for conducting cyber attacks, they may also be used to defend against cyber attacks 27,28. LLMs can significantly enhance threat detection and response capabilities by automating the analysis of vast amounts of data in real time. For instance, LLMs can identify subtle patterns and anomalies indicative of cyber attacks, such as malware distribution, phishing attempts, and unauthorized intrusions, enabling faster and more accurate threat identification. Furthermore, these models support the automation of routine cybersecurity tasks such as patch management, vulnerability assessments, and compliance checks, which alleviates the burden on cybersecurity teams and allows them to focus on more complex challenges. Additionally, LLMs can improve incident response by providing rapid analysis and suggesting appropriate mitigation strategies, thus shortening the time to respond to threats and potentially reducing the impact of breaches. The versatility of LLMs extends to enhancing the capabilities of cybersecurity chatbots, which can offer real-time assistance, incident reporting, and user interaction, further integrating AI into the daily operations of cybersecurity frameworks.
3.3 Intellectual property and data privacy challenges
There are several intellectual property (IP) and data privacy challenges related to LLMs. Firstly, LLMs are typically trained on vast amounts of data sourced from various providers. Ensuring that data is used legally and ethically involves:
-
Licensing Agreements: Formal agreements with data providers specifying the scope and terms of data usage.
-
Compliance: Adhering to legal requirements and ensuring that the data usage aligns with the terms set by the providers.
-
Transparency: Maintaining transparency in how data is sourced and used to build trust and avoid legal disputes.
-
Authorship: Determining whether the outputs of LLMs can be considered original works and who holds the rights to these creations. This involves proper citation of sources to avoid plagiarism.
Companies need to carefully evaluate commercial use of LLM-generated content, especially when it is derived from data with specific licensing agreements. The evolving legal landscape around AI-generated content, which may vary across jurisdictions, needs to be closely monitored.
Another issue with LLMs is the protection of data privacy, both during training and use. One thing is the leak of sensitive information from the training data. Another is the leak of sensitive information from system prompts that are supposed to be secret, for example though jailbreaks. Even if only the embedding vectors of user prompts are sent to a model, there exist the possibility that the prompt may be reconstructed using embedding inversion techniques 25.
The IP challenges related to LLMs are multifaceted and require careful consideration of legal, ethical, and technical aspects. Collaboration among stakeholders, including data providers, AI developers, and legal experts, is crucial to navigate these challenges effectively and ensure the responsible development and deployment of LLMs.
Federated learning (FL) is a technique that enables training models across decentralized devices or servers holding local data samples without exchanging them. FL allows different actors to collaboratively train models without sharing proprietary data, thereby preserving IP rights. This has also been applied to training LLMs, however researchers have shown that FL on text is vulnerable to attacks 29. Data can also leak during use of LLMs. Differential privacy is a way to add noise to training data or embedding vectors to protect privacy and give probabilistic guarantees on data leaks 30.
3.4 Environmental and social impacts
The risks related to LLMs are not only related to how they are used. There are also environmental and social impacts from how they are developed, operated and managed.
Environmental impacts The training and running of LLMs consume natural resources, including land, energy and water (see for example 31, 32,33,34): - Land: The increasing computational demands for training and running large language models requires more data centers that consume space. The construction of data centers may impact local biodiversity and have other environmental impacts. - Energy: The running of data centers used for training and hosting language models consumes large amounts of energy. Energy from fossil fuels may have an impact on the climate. Additionally, energy production and transmission consumes land areas, and the increased energy demands from data centers can put pressure on the electricity markets and increase prices for consumers and other industries. - Water: The cooling of data centers is typically done with water, which is already a scarce resource in many locations.
Viewed in isolation, these mentioned aspects of resource use may appear negative for society. However, the net impact depends on what the language models are used for and how they replace other technologies and activities that also have an environmental footprint. Moreover, the impacts are expected to change over time as technologies develop and technology adoption evolves.
Social impacts Human resources are also used in the development of LLMs, and there have been concerns about working conditions and job security (see for example 35,36):
-
Working conditions: Humans are needed for the curation of data, data labelling, and evaluation of model output, and moderation of unwanted responses. This has raised concerns about working conditions for people involved, including the workload, pay, and possible exposure to traumatic material.
-
Job security: LLMs can automate certain tasks that previously depended on more human effort. This may have consequences for the workforce in many industries, especially for jobs that involve processing large amounts of data, producing and presenting content, or handling many requests
While the effect on working conditions is an obvious legitimate concern, the effect on jobs is highly uncertain. New professions may arise as others decline as a result of AI, just like they have with the introduction of other technologies. The introduction of new tools may automate some tedious and repetitive tasks, and create new opportunities to do things that were not possible before. As an example, LLMs have already impacted journalism by helping or automating the writing of articles. This may not necessarily reduce the demand for journalists, but could also lead to broader and more personalised content, and free up time for journalists to do better research. Voice-enabled models may reduce the demand for humans on radio and TV, and the possibility of generating or cloning voices may be a threat to voice actors. On the other hand, voice models make it possible for users to engage with more content via sound and speech, possibly expanding the reach of the content and creating additional revenue streams and jobs.
3.5 Business implications of technological and legal developments
The emergence of LLMs has many impacts on businesses, including legal and strategic aspects. On the legal side, companies are bound by legislation in their business areas, but may also be subject to new AI specific regulations. For example, the EU AI act 37 put legal obligations on companies deploying or providing AI in the European Union, including LLMs. At the moment, it remains uncertain how to comply with these regulations, as the harmonized standards and best practices are under development. Moreover, when the roles of a company are blurry or shift over time, it may become challenging to know if legal obligations are met. The fact that legislation concerning LLMs differs between regions can also have implications for competition and access to models. For example, some commercial LLMs are not available to users in the European market today due legal concerns.
Beyond the legal aspects, there are also strategic concerns relating to LLMs. The science and engineering of LLMs have advanced rapidly over the past few years, and more actors have entered the market with commercial or open-source alternatives. In this evolving market, a company may want to swap the LLMs they use due to improved performance, or changes in licensing terms, costs or pricing models. Although LLMs are typically called via APIs that can easily be swapped, the “scaffolding” used for one model may not work well for another. For example, the “prompt engineering” and fine-tuning needed to make a model behave as desired can change significantly as models are swapped (although this can be mitigated to some extents by algorithmically optimizing prompts and weights for the new model with frameworks such as DSPy 38). For a company that wants to use language models today, it is crucial to think about how the system will age, what will be required to maintain it and what parts of the system require flexibility.
LLM advances also have implications in terms of infrastructure needs and investments, both on company, national and international level. Training of large AI models such as LLMs requires high-performance servers and Graphics Processing Units (GPUs) or Learning Processing Units (LPUs). Training and running models requires advanced data centers equipped with the latest cooling and security technologies are vital for housing and managing the extensive hardware required by LLMs. On top of this, robust networking infrastructure and cybersecurity measures are essential to protect LLM operations from cyber threats and ensure seamless connectivity. Reliable and secure access to computing infrastructure is a major business risk for companies that want to leverage LLM technology.
4 Preventing and mitigating risks associated with language models
Given the risks described in the previous section, LLMs must be used with caution and consideration of safefety, security, sustainability and ethics. In this section we describe some approached to reduce the risks, but also the limitations of these approaches. The main strategy to control LLM risk is careful consideration of how we use such models and the barriers we put in place to prevent and mitigate harm.
4.1 Guardrails and barriers
LLM guardrails are mechanisms designed to ensure that the outputs of LLMs align with desired safety, ethical, and accuracy standards 39,40. They can be implemented at different stages of the model's lifecycle, including during training, inference, and post-processing. While the term guardrails is popular in the AI community, the term barrier is used in many high-risk industries to describe ways to prevent unwanted events or mitigate harmful consequences if such events happen 41. Barriers could be technical, operational or organizational.
While no individual guardrail/barrier is perfect, adding several layers of guardrails/barriers can significantly reduce the probability of unwanted LLM output. Examples of such guardrails/barriers include:
-
Preambles to Prompts: One method to guide LLM behavior is by adding preambles or specific instructions to prompts. These preambles can set the context, specify rules, or outline ethical considerations that the LLM should follow when generating responses. For example, a preamble might instruct the LLM to avoid generating content that could be harmful, offensive, or misleading. (This is not immune to jail-breaks, see section 3.2).
-
Verification of queries: The response of an LLM can be sensitibe to the clarity of the prompt. It is therefore important to verify that the prompt has been correctly interpreted, for example by asking users if the understanding of a request is correct.
-
Prompt screening and filtering: Prompts should be screened to avoid off-topic requests that the model is not meant to answer. In addition to prompt engineering, rule-based systems can be used to filter and modify outputs. These systems can flag or alter responses that do not comply with predefined rules. This method ensures that any potentially harmful or inappropriate content is caught and corrected before reaching the end user.
-
Operational restrictions: The potential of harm from a model depends on how it is used. Therefore, the use should ideally be restricted based on the model's capabilities. This may involve access restrictions and the definition of strict workflows to limit the potential uses, as well as disclaimers and guidelines for use.
-
Workflows with multiple LLMs: Another approach involves using several LLMs in a workflow. Different models can be specialized for various tasks, such as content generation, ethical review, and factual verification. By combining these models, organizations can create a robust system where one model generates content, another checks for adherence to ethical guidelines, and a third verifies the accuracy of the information. (In terms of vulnerability to jail-breaks, it is more difficult to trick several models than to trick one model.)
-
Human-in-the-Loop: Incorporating human oversight is another critical guardrail. Human reviewers can monitor and evaluate the outputs of LLMs, providing an additional layer of scrutiny. This hybrid approach leverages the efficiency of LLMs with the nuanced judgment of human reviewers to ensure high-quality and safe outputs.
-
Monitoring and feedback loops: Continuous monitoring and feedback loops are essential to keep LLMs aligned with desired behaviors. By analyzing the performance and outputs of LLMs over time, developers can identify areas for improvement and adjust the guardrails accordingly. This ongoing process helps maintain the effectiveness of the guardrails in dynamic environments. By incorporating these guardrails, developers can enhance the reliability, safety, and fairness of LLMs, making them more suitable for real-world applications.
-
Transparency and explainability: Providing transparency about how LLMs work and the data they are trained on can help users understand the limitations and potential biases of the models. Explainability techniques can also aid in interpreting model decisions, making it easier to identify and correct errors.
-
Ethical guidelines and governance: Developing and adhering to ethical guidelines and governance frameworks is essential for ensuring responsible LLM use. This includes defining acceptable use cases, monitoring for misuse, and implementing mechanisms for accountability and redress.
-
User education and awareness: Educating users about the capabilities and limitations of LLMs is crucial. Users should be aware of potential risks, such as misinformation or biases, and be equipped with strategies for critically evaluating model outputs.
4.2 Enhancing LLMs with reliable knowledge
An obvious strategy to reduce LLM hallucinations is to ensure the LLM has access to reliable knowledge. If we want to apply an LLM in a specific domain, there are several methods that can be used:
-
Fine-tuning: Fine-tuning involves adapting a pre-trained model to specific tasks or use cases 42. In traditional fine-tuning, the entire model is retrained, which is resource-intensive, especially for large models with billions of parameters. LoRA (Low-Rank Adaptation) addresses this issue by freezing the pre-trained model weights and introducing low-rank matrices that only update certain parts of the model during training. This method is particularly useful for applications where multiple tasks require fine-tuning, as it enables fine-tuning large models on specific tasks without needing to retrain or store the entire model for each task, offering scalability and flexibility.
-
In-context learning: In-context learning involves providing examples of the desired task directly in the prompt, allowing the model to infer how to perform the task based on these examples 43. For example, if you provide an LLM with several examples of question-answer pairs, it will use those examples as "context" to generate answers for new questions. To instruct an LLM using examples is often simpler than coming up with detailed instructions of what you want the model to do.
-
Knowledge editing: Another way to modify LLM behaviour is knowledge editing. This involves making targeted adjustments to a model's stored information or parameters to correct errors or update its knowledge base without retraining the entire model 44. This process is crucial for maintaining the accuracy and relevance of LLMs as new information becomes available or inaccuracies in their outputs are identified. Techniques for knowledge editing include directly modifying specific model parameters (i.e., ROME and T-Patcher), using crafted prompts to influence outputs (i.e., MemPrompt, MeLLo, and IKE), conducting limited fine-tuning with new data, or integrating external modules that can override the model's responses (i.e., GRACE). This capability allows LLMs to be adapted swiftly to new data or corrections, ensuring they remain useful and reliable in various applications.
-
Retrieval-augmented generation (RAG): This is an alternative method to fine-tuning that retrieves relevant information from an external knowledge source instead of relying on the parametric memory of the LLM itself 45. The retrieved information is used to augment the input prompts and give the LLM context that it can use to generate its answer. The majority of RAG tools rely on data stored in a vector database (i.e. databases that store embedding vectors for chunks of text) and relevant information is retrieved based on vector similarity. This capability to add knowledge sources without retraining the LLM significantly lowers data requirements and enhances flexibility. A limitation is that RAG bases retrieval on vector similarity between sequential chunks of text, but the answers to a query may not lie within a single chunk, but require an overview of the totality of a document.
-
Graph RAG: This method extends RAG by incorporating structured knowledge from knowledge graphs. For example, GraphRAG 46,47, a library developed by Microsoft Research, employs a retrieval path that includes a knowledge graph. By leveraging graph-based data structures, Graph RAG can provide more precise and contextually relevant information, improving the model's ability to generate accurate and coherent responses. Traditional RAG techniques often struggle to maintain and comprehend the entities and relationships among documents. They perform poorly when tasked with holistically understanding summarized semantic concepts over a large data collection. GraphRAG can overcome the above-mentioned limitation of RAG by making a knowledge graph out of a document or database to capture relevant relationships that can help it answer questions that cannot be answered based on a single vector similarity search against separate chunks of data.
-
Giving access to structured knowledge: Just like we can use LLMs to retrieve information from vector databases using RAG, we can also use LLMS to help us retrieve information from traditional (non-vector) databases, including relational databases and knowledge graphs. For a human, it takes skill and effort to formulate the right searches, but this is something an LLM are very good at. By giving LLMs access to execute database searches, it may retrieve information and use this to either give a final response or make new searches to gather additional information. In that way, an LLM can become a convenient user interface to existing knowledge bases.
Various approaches are being proposed to improve RAG and Graph RAG. For example, HybridRAG 48 is a method that seeks to combine the strengths of standard RAG with graph RAG to create a more robust system for retrieving information by combining information retrieved with both methods. An alternative approach to improve RAG without using knowledge graphs is chunk enrichment 49, i.e. to augment the indexed chunk of text with metadata about the context it is taken from, for example, summaries of the document it belongs to.
RAG pipelines can be complicated, especially when incorporating knowledge graphs. The back-and-forth communication between the model and databases can make responses slow and consume a lot of tokens, which adds costs. Another important consideration is the time, effort and resources needed to build, verify and maintain knowledge graphs, especially when scaling up to large knowledge bases. The quality and coverage of the knowledge graph are heavily dependent on the input data sources. If the underlying data is incomplete or biased, it can limit the effectiveness of Graph RAG.
Recent advances in hardware and algorithms have expanded the context lengths that models can handle, leading to questions about the need for retrieval systems. For example, recent advancements allow LLMs to process extensive inputs, as seen in models like Gemini 1.5, capable of handling up to 2 million tokens, and Claude 3, with a capacity of 200,000 tokens. However, LLMs tend to underutilize long-range context and see declining performance as context length increases, especially when relevant information is embedded within a lengthy context. Moreover, practically, the use of long contexts is expensive and slow. This suggests that selecting the most relevant information for knowledge-intensive tasks is crucial. In any case, very large knowledge bases will never fit in the context of any LLM, and we will have to resort to retrieval methods.
4.3 Augmenting LLMs with computation abilities and tools
In the same way that one may give LLMs access to perform searches in knowledge bases, one can in principle give them access to use any tool or software. This may include calculators, simulation software, symbolic reasoning engines, internet search engines, and so on. Tool use can vastly expand the capabilities of an LLM, and is a way of reducing hallucinations. A tool may be very specific or very general. For example, a specific tool may compute a particular formula, whereas a general tool may allow execution of arbitrary code. It is possible to make AI agents that decide themselves when and how to use tools. However, in such cases there are still challenges with the LLMs reliably invoking the correct tools and using them optimally. A more reliable approach is to restrict the tool use to pre-defined workflows, where the LLMs lingustic abilities is merely exploited as an interface.
LLMs can be convenient linguistic interfaces between users and tools, or between different tools. Specifically, a software tool requires inputs in particular formats and produces outputs in particular formats, and LLMs can be used to convert between these formats and natural language. OpenAI has introduced the option of structured output in their API 50, allowing one to specify a desired JSON schemas for the output that the model reliably adheres to. This capability is very useful for integrating LLMs with tools and as part of automated workflows where different components and systems need to exchange information reliably.
When it comes to data protection, the use of tools limits what data you need to send to LLMs (potentially external cloud providers). This is because you can make the tools run locally or on local servers and exchange data via files that the LLM will never see. The latter also reduces the token consumption of the LLM, as less information is exchanged via prompts.
There is a risk that LLMs with access to tools may cause harm with the tools. Therefore the tool access should be limited. For example, an LLM should only be allowed to run code in a safe sandbox environment. In complex worklflows, human oversight is also important. By making the communication between the LLM and the tools transparent to users, humans may verify that the answer are trutworthy, and humans may be put in-the-loop to authorize further actions.
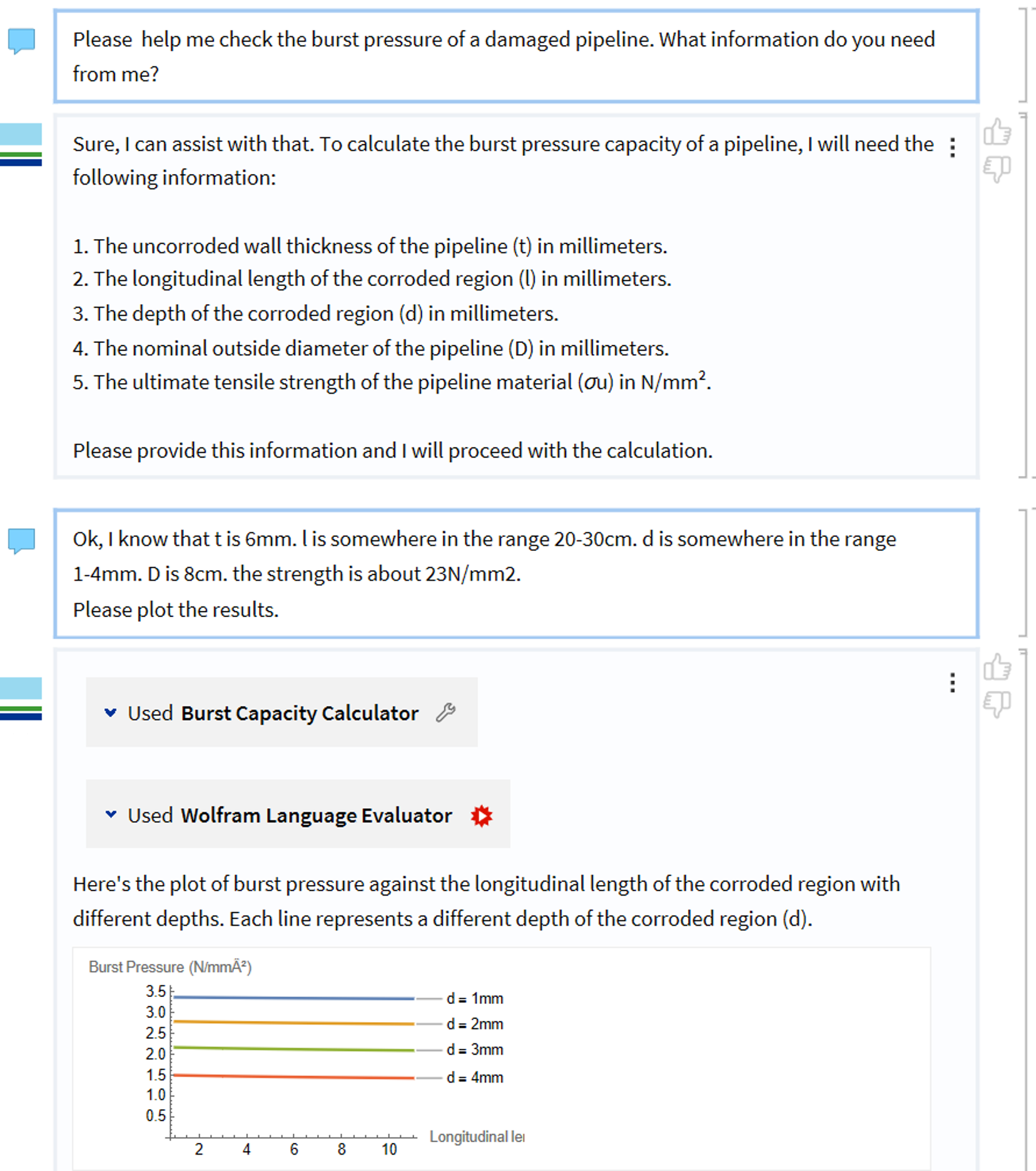
Figure 4: Example of LLM using tools.
4.4 Preference optimization and fine-tuning of model behaviour
Many approaches are used to modify LLM behaviour to prevent harmful output and reduce hallucinations.
-
Reinforcement Learning with Human Feedback (RLHF): RLHF is a method where human feedback is used to train LLMs 51. By incorporating human judgments about the quality of the model's outputs, RLHF aims to fine-tune the model to align better with user preferences. This technique leverages reinforcement learning algorithms to optimize the model's performance based on the provided feedback.
-
Proximal Policy Optimization (PPO): PPO is a reinforcement learning algorithm that is commonly used in the context of RLHF 52. PPO strikes a balance between exploration and exploitation by using a clipped objective function to ensure that updates to the policy do not deviate excessively from the current policy. This helps in maintaining stable training and improving the performance of LLMs when fine-tuning them based on human feedback.
-
Direct Preference Optimization (DPO): DPO is another technique for optimizing LLMs directly based on user preferences 53. Unlike RLHF, which may involve indirect measures of performance, DPO focuses on directly optimizing the model to produce outputs that align with explicit user preferences. This method can be particularly effective when precise preference data is available, allowing for more targeted fine-tuning of the model.
-
Supervised Fine-Tuning (SFT): SFT involves training LLMs on labeled datasets where the desired outputs are known 54. This method uses supervised learning techniques to adjust the model's parameters to improve its performance on specific tasks or domains. SFT is often used as an initial step before applying more advanced techniques like RLHF, providing a solid foundation for further optimization.
In a comprehensive study, PPO surpassed other alignment methods in all cases and achieve state-of-the-art results in challenging code competitions 55, while others claim that there exist more efficient methods 56. However, other research has shown that incorporating safety mechanisms through preference optimization and fine-tuning of LLMs can impact their general performance 57.
Unfortunately, preference optimization and fine tuning are not bullet-proof techniques for avoiding harmful output, as there are jailbreaks to make override how the model has been trained to behave (see section 3.2). One simple attack method that often works is to give unsafe prompts in a language that is different from the main language the model has been trained on 58. Multilingual LLM safety is therefore an ongoing challenge that is drawing researchers’ attention (see e.g. 59).
4.5 Uncertainty quantification
There are several reasons why one would like LLMs to know what they don’t know and express how confident they are. Information about uncertainty can help users judge how much they should trust the LLM. Statements about uncertainty can add transparency to decision processes, sometimes demanded by regulations. Furthermore, understanding uncertainty is crucial for addressing issues such as hallucinations, where LLMs generate plausible-sounding but factually incorrect outputs. Expression of uncertainty may also be used to filter LLM answers and only return responses scoring above some confidence threshold.
Uncertainty quantification in neural networks has always been a challenging task, particularly in the context of natural language processing, where it has traditionally been applied to classification tasks. However, with the advent of LLMs, there is an increased focus on uncertainty quantification in generation tasks, where the model must generate coherent and contextually relevant text rather than simply classify an input into some predefined categories.
Uncertainty can be elicited from an LLM in different ways. One approach is to let the LLM explicitly verbalise its judgement of uncertainty. This requires prompt engineering to teach the LLM how to express uncertainty. A problem with this approach is that the LLM may hallucinate in its responses about uncertainty, and one may ask how uncertain it is about its uncertainty, and so on. A second approach is to use the log-likelihood from the LLM output layer to judge confidence in answers. However, this can be unreliable simply because there are many different ways to answer a question correctly. A third approach is to send the same prompt several times to the LLM and to classify the responses and quantify uncertainty based on the frequency of answer categories. A concern with this approach is whether the obtained uncertainty quantification is calibrated to the underlying data. An important challenge here is differentiating between token-level uncertainty, which considers the model’s confidence in predicting each word, and sequence-level uncertainty, which assesses the confidence in the entire generated text. While most UQ studies focus on the former, the latter remains more complex due to the vast output space and potential for diverse and valid responses.
There is a difference between closed questions that have a truth value, versus open-ended questions that have complex or ambiguous truth values. Closed questions lend themselves more easily to uncertainty quantification because the model can be trained to recognize correct and incorrect answers explicitly. For open-ended questions, uncertainty quantification becomes more challenging due to the subjective nature of the responses.
Recent research work on uncertainty quantification for LLMs tries to distinguish between uncertainty and confidence 60. Uncertainty relates to the model’s ambiguity or the spread of potential predictions, while confidence pertains to the model’s belief in a specific prediction. These concepts are further nuanced by distinguishing between epistemic and aleatoric uncertainty. Epistemic uncertainty arises from the model’s lack of knowledge and can often be reduced with more data and better training, whereas aleatoric uncertainty is due to the inherent variability or noise in the task and cannot be reduced by improving the model 61, 62.
Irrespective of the approach used, an expression of uncertainty is not helpful unless it is rooted in reality, which requires some effort for ensuring calibration. Some methods for uncertainty quantification and calibration for LLMs include:
-
Introspection: This involves the LLM assessing its own confidence in the generated responses, often requiring specialized training or fine-tuning to improve self-assessment capabilities. For example a model may be fine-tuned on a dataset that includes information about uncertainty, such as labels indicating the confidence level of each answer 63. However, this may be difficult for open-ended questions. This technique may be less effective for open-ended questions or tasks without clear ground truth, requiring careful calibration to avoid overconfidence.
-
Model-based oversight: This technique uses a secondary model to oversee the primary model's outputs and provide a confidence score. The oversight model can be trained on labeled data to recognize patterns associated with high or low confidence. This approach aligns with the supervised methods, such as white-box, grey-box, and black-box supervised uncertainty estimation, where different levels of access to the model’s internal states are used to construct features for the oversight model.
-
Mechanistic interpretability: This approach aims to understand the internal workings of the LLMs 64. By interpreting the mechanisms of how the model generates answers, one can infer the confidence level of specific responses. Some have hypothesized that LLMs contain special entropy neurons that can be probed for uncertainty 65. However, not all uncertainty quantification methods rely on access to the LLM’s internals, some operate purely on the generated text, making them more applicable in settings where the model’s architecture or parameters are inaccessible.
-
Cheat correction: This approach teaches models to cheat by training it on pairs of independent responses from different experts. It is then allowed to cheat by observing one of the responses to predict the second response, and the idea is that the model only need to cheat when there is something I doesn’t know 66.
-
Calibration techniques and Conformal Prediction: Methods like temperature scaling adjust the predicted probabilities to better match actual likelihoods, improving model reliability. Conformal prediction provides a robust framework to ensure that the true output falls within a predicted set at a specified confidence level 67.
-
Unsupervised approaches: They involve analysing the distribution of the LLM’s output probabilities (entropy) or the semantic similarity between multiple generated reponses. High entropy or low semantic similarity across outputs indicates high uncertainty. This is particularly useful in black-box settings, where access to the model’s internals is limited, and only generated text can be analyzed.
Despite much research into LLM uncertainty quantification and calibration, researchers have shown that LLM uncertainty is fragile, and that it is possible to embed a backdoor in LLMs that manipulates its uncertainty without affecting its answers 68. This fragility highlights the need for robust uncertainty quantification techniques that can differentiate between genuine uncertainty and manipulation, further complicating the task of developing trustworthy LLMs.
5 The trends and future impacts of LLMs
Over the past two years, we have seen rapid advances in AI for language processing and generation. At the moment, we see several interesting developments:
- Faster throughput: The latest iteration of LLMs, exemplified by LLama3 in the Groq cloud69, has achieved remarkable throughput speeds, now capable of processing 870 tokens per second. This pace far surpasses human cognitive speed, marking a critical milestone in the journey toward an intelligence revolution. The ability of AI agents to engage in real-time interactions opens new avenues for user interfaces, automation and decision-making. Such agents can process complex queries, generate insights, and deliver results almost instantaneously. This widens the range of possible applications.
- Longer context: Recent LLMs are able to handle much larger context windows than previous models, allowing for the processing of more content. For example, the latest Gemini models from Google have 1-2million token context windows, compared to 4k tokens for the original ChatGPT. This enhances their ability to maintain coherence and relevance over extended interactions, making them more effective in applications like book summarization and long-form content generation.
- Multimodality: LLMs are increasingly integrating multimodal capabilities, allowing them to process and generate content across different types of media, such as text, images, and audio. This trend paves the way for more comprehensive AI applications that can understand and generate content in a more human-like manner, such as creating detailed image captions or video descriptions. Some leading multimodal LLMs at the time of writing include GPT-4o from OpenAI, LLaMA 3.2 from Meta, Claude 3.5 from Anthropic, and NVLM from Nvidia.
- Smaller and more efficient models: Efforts to reduce model size while maintaining performance are gaining traction. Techniques like distillation, quantization, and pruning are being employed to create models that are both cost-effective and energy-efficient, making advanced AI accessible to a broader range of applications and devices. Smaller models provide faster inference times, essential for real-time applications.
- Computation enhanced generation (CAG): This term was coined by Stephen Wolfram as a contrast to RAG (retrieval augmented generation) 70. This trend involves the integration of external computational tools and models with LLMs to enhance their generative capabilities. By combining the strengths of LLMs with specialized computational resources, it's possible to generate more accurate responses to complex questions that rely on computation.
- Dynamic prompting: Dynamic Prompting is an innovative method in Generative AI that creates prompts in real-time by considering user behaviour, context, and enterprise data, contrasting with the static nature of traditional prompts 71. This opens up new possibilities for personalization and contextualization of LLM responses.
- LLMOps: As the deployment of LLMs becomes more widespread, operationalizing these models, known as LLMOps, has emerged as a critical focus area. This involves developing robust pipelines for training, deploying, and managing LLMs in production environments, ensuring they are reliable, scalable, and aligned with business goals. This also creates an LLMOps service market, which links to a market for assurance of AI-enabled systems (see e.g. DNV-RP-0671 72 and DNV-RP-0665 73).
- Test-Time Compute (TTC): Test-time Compute (TTC), also known as Inference Time Scaling (ITS), refers to dynamic allocation of computational resources during inference, used by current leading AI models like OpenAI’s o1. Depending on the prompt complexity, such models may decide to employ approaches to improve the quality of the final output, for example chain-of thought reasoning, voting over many sampled responses, Monte Carlo tree search, use of verifyer models, or other 'tricks' 74.
- Continued reliance on humans: After the breakthrough of LLMs, many believed that traditional job roles would decline and that “prompt engineering” was the new “data science”. However, time has shown that “prompt engineering” can be automated to a great extent, while LLMs are yet to replace many jobs. Looking ahead, it is likely that LLMs will continue to assist with tedious tasks, however, companies will still rely on humans. It is more difficult than anticipated to use LLMs effectively in organizational contexts. Also, LLMs are mostly good at handling existing knowledge, but not good at generating new knowledge needed to drive growth and sustainable development.
- Good old NLP: Natural language processing (NLP) is an old research field, and a lot of good models existed before the LLM era. While LLMs excel at generating human-like text and responding to a wide range of tasks, traditional NLP can often achieve high accuracy in specialized tasks such as syntax parsing, entity recognition and topic modelling. Such specialized models are smaller and can be trained and used at a fraction of the cost of LLMs. Such models can also play a role in combination with LLMs to improve LLM performance.
6 Conclusion
There is no doubt that LLMs can have an impact on business and industries. Among the key advantages they bring are the ability to function as a natural language interface between humans and computers, their versatility to be applied across a wide range of tasks, and their ability to process large amounts of text quickly.
Despite some hyped claims about LLMs’ emergent properties, it seems clear that LLMs are responding based on learnt (or perceived) patterns rather than actual reasoning or computation. To reduce hallucination and improve the reliability of information, LLMs can be connected to other trusted information sources and tools. LLMs should not be used as the main computational engine or source of knowledge, but rather as linguistic interfaces to other software systems and knowledge sources.
The harm from LLMs does not only stem from their limitations and weaknesses, but also from their strengths. LLMs can be used by adversaries to perform cybercrime and other malicious activities. Also, even when used with good intentions, LLMs do not come out of the box with the ability to criticize themselves and express uncertainty. They can sometimes be “confidently wrong” which could lead to unwanted consequences if we rely on the models too much.
LLM providers, deployers and users should be aware of risks related to data leaks and violations of intellectual property, and should take measures to protect sensitive data. Use of third-party LLM API services or web services could inadvertently expose sensitive internal knowledge, information, and data to these external entities. Generated output may also infringe on copyrights, so one should be careful to cite sources of information. Those training or fine-tuning LLMs should obtain consent from data providers.
Individuals and companies should be careful in applying LLMs to critical tasks. Different guardrails can be applied to reduce the probability of unwanted output, such as barriers that can detect off-topic questions and confirm user queries before providing answers. However, no guardrail is perfect, and one should be aware of the possibility of jailbreaks that can bypass them.
Companies wishing to use LLM should also consider alternatives to LLMs that may be more efficient, reliable and sustainable for their use cases. If deciding to use LLMs, it is also important to not be over-reliant on models that may be outdated or have new licensing terms or cost models tomorrow. It is crucial to adopt good "LLMOps" and to build the ‘scaffolding’ around the models in such a way that the system can be easily maintained in the future.
In conclusion, as LLM technology advances rapidly, it is important to maintain a sceptical and cautious attitude to avoid unacceptable risks in business and production environments.
References
-
Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017). ↩
-
Devlin, Jacob, et al. "BERT: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018). ↩
-
Radford, Alec, et al. "Improving language understanding by generative pre-training." (2018). ↩
-
Taylor, Wilson L. "“Cloze procedure”: A new tool for measuring readability." Journalism quarterly 30.4 (1953): 415-433. ↩
-
Warwick, Kevin, and Huma Shah. "Can machines think? A report on Turing test experiments at the Royal Society." Journal of experimental & Theoretical artificial Intelligence_ 28.6 (2016): 989-1007. ↩
-
OpenAI. “Introducing ChatGPT”. Published November 30, 2022. https://openai.com/index/chatgpt/ ↩
-
Kutuzov, Andrey, et al. "Large-scale contextualised language modelling for Norwegian." arXiv preprint arXiv:2104.06546_ (2021). ↩
-
Zhao, Jinman, et al. "Gender Bias in Large Language Models across Multiple Languages." arXiv preprint arXiv:2403.00277_ (2024). ↩
-
Liu, Nelson F., et al. "Lost in the middle: How language models use long contexts." Transactions of the Association for Computational Linguistics_ 12 (2024): 157-173. ↩
-
Shumailov, Ilia, et al. "AI models collapse when trained on recursively generated data." Nature 631.8022 (2024): 755-759. ↩
-
Ali, Mehdi, et al. "Tokenizer Choice For LLM Training: Negligible or Crucial?." arXiv preprint arXiv:2310.08754_ (2023). ↩
-
Stribling, Daniel, et al. "The model student: GPT-4 performance on graduate biomedical science exams." Scientific Reports 14.1 (2024): 5670. ↩
-
Kambhampati, Subbarao. "Can large language models reason and plan?." Annals of the New York Academy of Sciences_ 1534.1 (2024): 15-18. ↩↩
-
Kahneman, Daniel. “Thinking, Fast and Slow”. New York: Farrar, Straus and Giroux, 2011. ↩
-
Valmeekam, Karthik, et al. "On the planning abilities of large language models - a critical investigation." Advances in Neural Information Processing Systems 36 (2023): 75993-76005. ↩
-
Lu, Sheng, et al. "Are Emergent Abilities in Large Language Models just In-Context Learning?." arXiv preprint arXiv:2309.01809 (2023). ↩
-
Trinh, Trieu H., et al. "Solving olympiad geometry without human demonstrations." Nature_ 625.7995 (2024): 476-482. ↩
-
https://www.linkedin.com/feed/update/urn
 activity:7154157779136446464/ ↩
activity:7154157779136446464/ ↩ -
Huang, Jie, et al. "Large language models cannot self-correct reasoning yet." arXiv preprint arXiv:2310.01798 (2023). ↩
-
Zou, Andy, et al. "Universal and transferable adversarial attacks on aligned language models." arXiv preprint arXiv:2307.15043_ (2023). ↩
-
Chao, Patrick, et al. "Jailbreaking black box large language models in twenty queries." arXiv preprint arXiv:2310.08419_ (2023). ↩
-
Mehrotra, Anay, et al. "Tree of attacks: Jailbreaking black-box LLMs automatically." arXiv preprint arXiv:2312.02119 (2023). ↩
-
Morris, John X., et al. "Text embeddings reveal (almost) as much as text." arXiv preprint arXiv:2310.06816 (2023). ↩↩
-
Xu, Jiacen, et al. "Autoattacker: A large language model guided system to implement automatic cyber-attacks." arXiv preprint arXiv:2403.01038 (2024). ↩
-
Hassanin, Mohammed, and Nour Moustafa. "A Comprehensive Overview of Large Language Models (LLMs) for Cyber Defences: Opportunities and Directions." arXiv preprint arXiv:2405.14487 (2024). ↩
-
Xu, HanXiang, et al. "Large language models for cyber security: A systematic literature review." arXiv preprint arXiv:2405.04760 (2024). ↩
-
Fowl, Liam, et al. "Decepticons: Corrupted transformers breach privacy in federated learning for language models." arXiv preprint arXiv:2201.12675_ (2022). ↩
-
Singh, Tanmay, et al. "Whispered tuning: Data privacy preservation in fine-tuning LLMs through differential privacy." Journal of Software Engineering and Applications 17.1 (2024): 1-22. ↩
-
Forbes (25 February 2024), "AI Is Accelerating the Loss of Our Scarcest Natural Resource: Water" ↩
-
The Guardian (07 March 2024), "AI likely to increase energy use and accelerate climate misinformation – report" ↩
-
The Guardian (01 August 2024) "Anger mounts over environmental cost of Google datacentre in Uruguay" ↩
-
The Financial Times (18 August 2024), "US tech groups’ water consumption soars in ‘data centre alley’" ↩
-
Time (18 January 2023), "Exclusive: OpenAI Used Kenyan Workers on Less Than $2 Per Hour to Make ChatGPT Less Toxic" ↩
-
The Atlantic (20 January 2023), "How ChatGPT Will Destabilize White-Collar Work" ↩
-
Tekgul, Hakan. "Guardrails: What Are They and How Can You Use NeMo and Guardrails AI To Safeguard LLMs?" ↩
-
"A Comprehensive Guide: Everything You Need to Know About LLMs Guardrails" ↩
-
Petroleum Safety Authority Norway (2017), "Principles for barrier management in the petroleum industry, BARRIER MEMORANDUM 2017" ↩
-
Dave Bergmann (15 March 2024), "What is fine-tuning?" ↩
-
Dong, Qingxiu, et al. "A survey on in-context learning." arXiv preprint arXiv:2301.00234 (2022). ↩
-
Zhang, Ningyu, et al. "A comprehensive study of knowledge editing for large language models." arXiv preprint arXiv:2401.01286 (2024). ↩
-
Lewis, Patrick, et al. "Retrieval-augmented generation for knowledge-intensive nlp tasks." Advances in Neural Information Processing Systems 33 (2020): 9459-9474. ↩
-
Edge, Darren, et al. "From local to global: A graph rag approach to query-focused summarization." arXiv preprint arXiv:2404.16130 (2024). ↩
-
Sarmah, Bhaskarjit, et al. "HybridRAG: Integrating Knowledge Graphs and Vector Retrieval Augmented Generation for Efficient Information Extraction." arXiv preprint arXiv:2408.04948 (2024). ↩
-
Bai, Yuntao, et al. "Training a helpful and harmless assistant with reinforcement learning from human feedback." arXiv preprint arXiv:2204.05862 (2022). ↩
-
Schulman, John, et al. "Proximal policy optimization algorithms." arXiv preprint arXiv:1707.06347 (2017). ↩
-
Rafailov, Rafael, et al. "Direct preference optimization: Your language model is secretly a reward model." Advances in Neural Information Processing Systems 36 (2024). ↩
-
Raffel, Colin, et al. "Exploring the limits of transfer learning with a unified text-to-text transformer." Journal of machine learning research 21.140 (2020): 1-67. ↩
-
Xu, Shusheng, et al. "Is DPO superior to PPO for LLM alignment? a comprehensive study." arXiv preprint arXiv:2404.10719 (2024). ↩
-
Ahmadian, Arash, et al. "Back to basics: Revisiting reinforce style optimization for learning from human feedback in LLMs." arXiv preprint arXiv:2402.14740 (2024). ↩
-
Deng, Yue, et al. "Multilingual jailbreak challenges in large language models." arXiv preprint arXiv:2310.06474 (2023). ↩
-
Yong, Zheng-Xin, Cristina Menghini, and Stephen H. Bach. "Low-resource languages jailbreak GPT-4." arXiv preprint arXiv:2310.02446 (2023). ↩
-
Üstün, Ahmet, et al. "Aya model: An instruction finetuned open-access multilingual language model." arXiv preprint arXiv:2402.07827 (2024). ↩
-
Lin, Zhen, Shubhendu Trivedi, and Jimeng Sun. "Generating with confidence: Uncertainty quantification for black-box large language models." arXiv preprint arXiv:2305.19187 (2023). ↩
-
Yadkori, Yasin Abbasi, et al. "To Believe or Not to Believe Your LLM." arXiv preprint arXiv:2406.02543 (2024). ↩
-
Ahdritz, Gustaf, et al. "Distinguishing the knowable from the unknowable with language models." arXiv preprint arXiv:2402.03563 (2024). ↩
-
Liu, Linyu, et al. "Uncertainty Estimation and Quantification for LLMs: A Simple Supervised Approach." arXiv preprint arXiv:2404.15993 (2024). ↩
-
Ferrando, Javier, et al. "A primer on the inner workings of transformer-based language models." arXiv preprint arXiv:2405.00208 (2024). ↩
-
Gurnee, Wes, et al. "Universal neurons in gpt2 language models." arXiv preprint arXiv:2401.12181 (2024). ↩
-
Johnson, Daniel D., et al. "Experts Don't Cheat: Learning What You Don't Know By Predicting Pairs." arXiv preprint arXiv:2402.08733 (2024). ↩
-
Su, Jiayuan, et al. "API is enough: Conformal prediction for large language models without logit-access." arXiv preprint arXiv:2403.01216 (2024). ↩
-
Zeng, Qingcheng, et al. "Uncertainty is Fragile: Manipulating Uncertainty in Large Language Models." arXiv preprint arXiv:2407.11282 (2024). ↩
-
Groq official website: https://groq.com/ ↩
-
Wolfram Technology Conference 2024: Stephen Wolfram's Keynote Address (just after 1:34:00) ↩
-
Avaamo (14 March 2024), “Introducing Dynamic Prompts: Unlocking Magic Without the Dark Arts” ↩
-
DNV Recommended practice for assurance of AI-enabled systems (DNV-RP-0671) ↩
-
DNV Recommended practice for machine learning applications (DNV-RP-0665) ↩
-
Prabhakar, Ajith Vallath. "Understanding Test Time Compute: How AI Systems Learn to Think in Real-Time" ↩